谈谈NLP中的终极问题
读了点书,写点笔记
歧义消除
分析特定的上下文的词被赋予何种意思。需要联系上下文,利用临近的词汇的相近含义。NLP中出现歧义的原因较多是因为是同一句句子可被分割为不同的结构,而不同的结构又能译出不同的意思。举个例子,如“咬死了猎人的狗”,“南京市长江大桥”等等,这些句子都能根据不同的结构分成不止一种的歧义。煎鱼所知道消除歧义的方法就两种(毕竟煎鱼读的书少),一是根据统计计算出跟普遍的用法,二则是将问题反问与用户。
第一种的话,也不需要太多地阐述,通俗点来讲就是看看这些歧义中,哪一种会被更多人接受。如“南京市长江大桥”,更多人认可是“南京市-长江-大桥”,而不是“南京-市长-江大桥”(当然煎鱼是讲得太过通俗了,这里的筛选其实是有严格的数据做支撑的)。
而第二种做法是煎鱼更为认同的,其实别说机器了,当我们人类遇到歧义时也是一脸懵逼的,所以当人类都不知道应该是哪一个意思的时候,为何要为难机器在这两个中选一个呢?更何况,概率小者也不该被忽略!而第二种做法就是:将问题反问给用户 —— 请问你说的是“南京-市长-江大桥”还是“南京市-长江-大桥”呢?
指代消除
通常需要分清某代词是指前文的主语还是宾语,例如“Fafa偷了煎鱼送给女朋友的项链,最后被警察捉了。”、“Fafa偷了煎鱼送给女朋友的项链,最后还是被归还了。”,究竟是哪个被警察捉,哪个被归还呢?这样的指代歧义想要消除就必须要理解前一句话整句话的意思 —— 这就有意思了,想要理解一句话,就要理解它前一句话的意思对吧(为啥我会想到0.5的无数次平方永远大于零)。
指代消除的一种做法是深度学习消除,可以参考《基于Deep Learning的代词指代消解》(奚雪峰,周国栋,2013.06),这里不作描述。
自动生成语言
主要在自动回答和机器翻译中常用,依赖于对文意的理解以及机器对人类语言结构的掌握。煎鱼个人觉得两个都是难点,理解文意就不用说了,一直是难点;而语言结构为啥说也很难呢,主要是人类这种神奇的东西,ta可以通过人类语言中原本有限的语法规则,组合成口语中无限的可能,你看看啥事宾语前置、状语后置、X语X置什么鬼的。当然你也可以说,过于口语的语法不给机器用就行了 —— 这样的确可以,但是不会自动学习新语法规则的人工智能是人工智能吗?
同时,机器也要掌握一定的语言风格,当然也可以模仿别的语言者(语言风格包含了口头禅、喜欢用的词语搭配、是否有文采等)。
机器翻译
机器翻译一直是语言理解的圣杯,它几乎是NLP的起源。可以说,机器翻译不仅要求机器充分理解句子的含义,而且还必须掌握了两门语言(甚至是历史文化)的异同。这样的工作,现在要求信雅达的翻译也得用人工,机器这是做不来!到现在,即使是大家大户的微软、谷歌等都没有一个较为完美的解决办法,可以说,它的解决方法是全人类都在寻找的(BTW,这个算是NP完全问题么)。
人机对话系统
煎鱼第一想到的就是这名的图灵测试了 —— 究竟机器与真人两者同时和你聊天,你最后是否真的能区分出哪个是人类,哪个是机器呢?
当然,广义的人机对话即是人机交互了(煎鱼的理解)。人机对话可通过多种形式进行,有字符、手势、语音、表情、肢体动作等。其中,比较热门的语音的交互形式包含了语音识别和句意解释,而语音识别在现在也已经比较成熟了(微信开发都已经标配了语音识别了,有兴趣的加煎鱼的小小机器人,然后用语音尝试一下)。而人脸识别也是较为成熟。。吧。
NLP流程
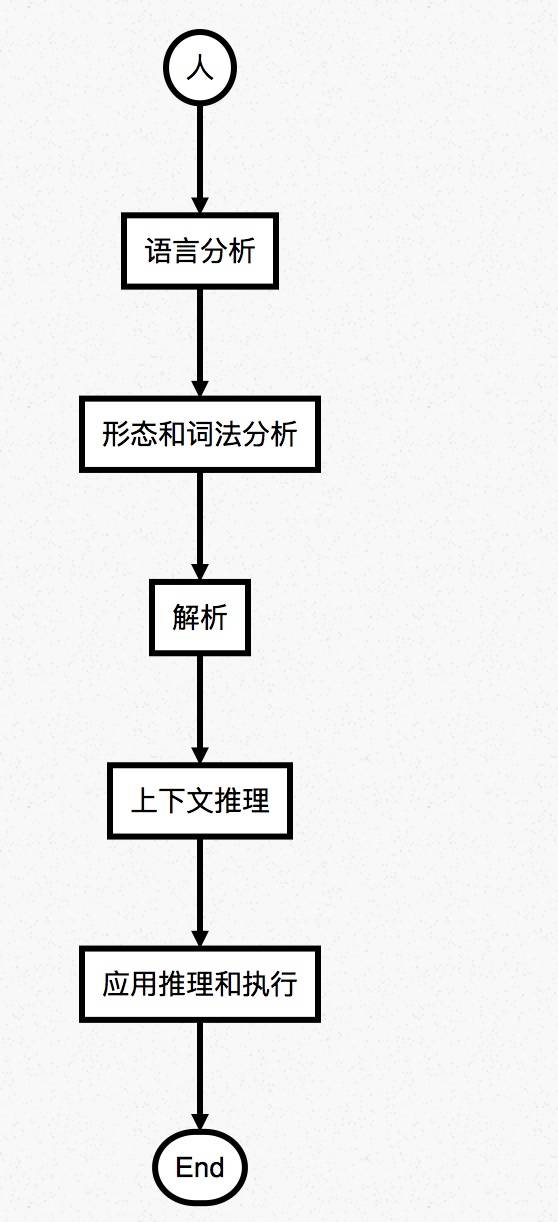
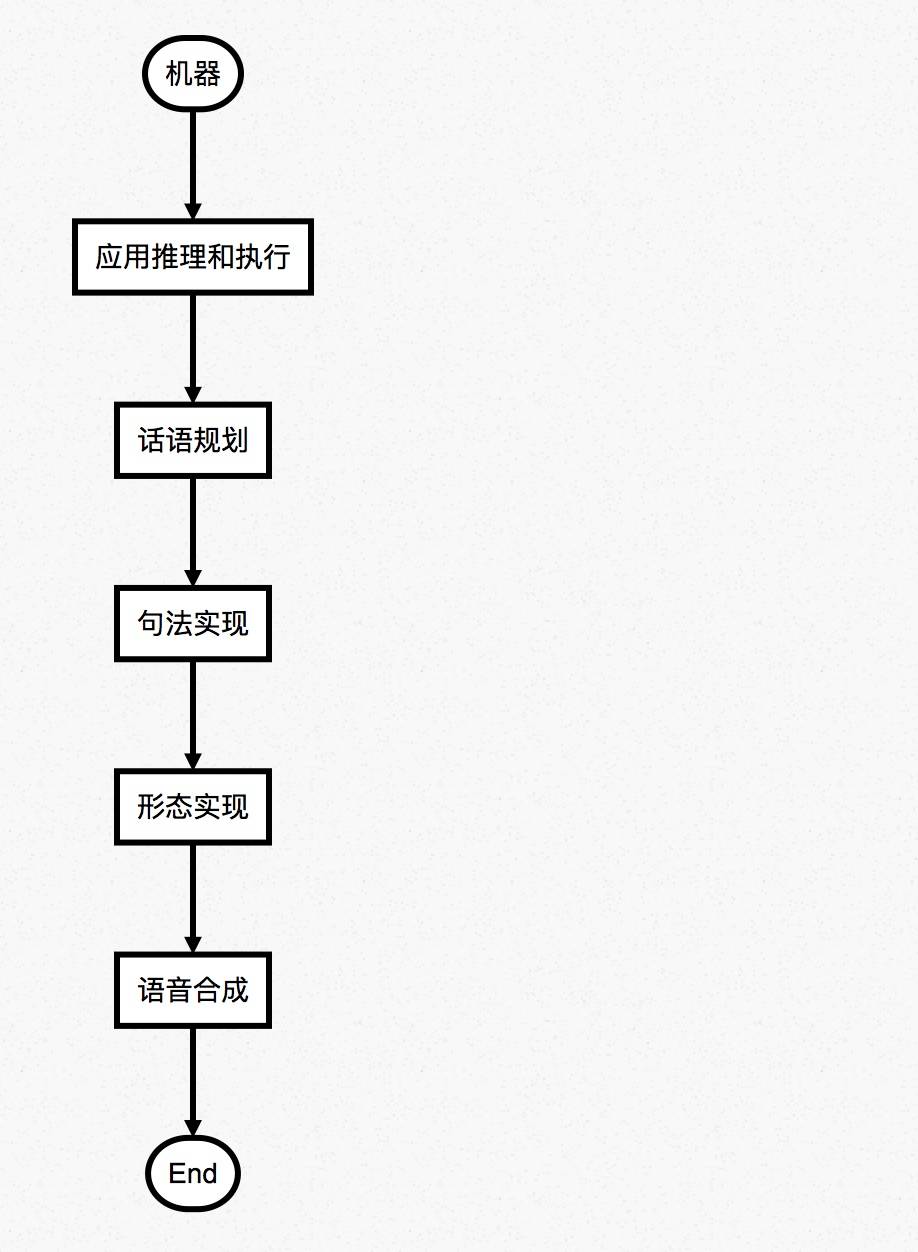
其中涉及:发音模型语位学(Phonology),形态规划形态学(Morphology),词汇和语法句法(Syntax),话语背景语义(Semantics),领域知识推理(Reasoning)。
若有错误之处请指出,更多地关注煎鱼。


