Python-OpenCV进行人脸识别
在之前的文章中,我们学习了使用数据集训练出一个识别器。本文中,我们将载入这个识别器,然后来看见怎么识别人脸。
如果看过之前的文章,你就已经准备好了一个识别器,它就在trainner文件夹和trainner.yml文件里面。
现在,我们将使用这个训练好的文件去识别人脸了。
导入
import cv2
import numpy as np
加载识别器
接下来,我们用OpenCV库以及我们训练好的数据(yml文件)创建一个识别器对象:
recognizer = cv2.face.LBPHFaceRecognizer_create()
# recognizer = cv2.createLBPHFaceRecognizer() # in OpenCV 2
recognizer.read('trainner/trainner.yml')
# recognizer.load('trainner/trainner.yml') # in OpenCV 2
然后用之前准备好的xml创建一个分类器:
cascade_path = "haarcascade_frontalface_default.xml"
face_cascade = cv2.CascadeClassifier(cascade_path)
获取到摄像头的控制对象:
cam = cv2.VideoCapture(0)
加载一个字体,用于在识别后,在图片上标注出识别对象的名字:
# font = cv2.cv.InitFont(cv2.cv.CV_FONT_HERSHEY_SIMPLEX, 1, 1, 0, 1, 1)
font = cv2.FONT_HERSHEY_SIMPLEX
识别程序的主循环
在程序的主循环中,我们需要做的是:
- 从摄像头中获取图像
- 将图像转换为灰度图片
- 在图片中检测人脸
- 用识别器识别该人的id
- 将识别出人脸的id或名称用矩形在图片中标出来
while True:
ret, im = cam.read()
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.2, 5)
for (x, y, w, h) in faces:
cv2.rectangle(im, (x - 50, y - 50), (x + w + 50, y + h + 50), (225, 0, 0), 2)
img_id, conf = recognizer.predict(gray[y:y + h, x:x + w])
# cv2.cv.PutText(cv2.cv.fromarray(im), str(Id), (x, y + h), font, 255)
cv2.putText(im, str(img_id), (x, y + h), font, 0.55, (0, 255, 0), 1)
cv2.imshow('im', im)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
recognizer.predict为预测函数,putText则是在图片上添加文字
更进一步
由于可能识别不出来,或者存在未知的人脸。而且,如果只用id1,id2就会大大地降低了程序的体验。因此,我们可以把id换成名字,把未知的脸标为未知。
我们把程序改成:
img_id, conf = recognizer.predict(gray[y:y + h, x:x + w])
if conf > 50:
if img_id == 1:
img_id = 'jianyujianyu'
elif img_id == 2:
img_id = 'ghost'
else:
img_id = "Unknown"
# cv2.cv.PutText(cv2.cv.fromarray(im), str(Id), (x, y + h), font, 255)
cv2.putText(im, str(img_id), (x, y + h), font, 0.55, (0, 255, 0), 1)
释放资源
记得释放资源
cam.release()
cv2.destroyAllWindows()
测试
然后在测试阶段,这个人工智障完美地识别不出我。
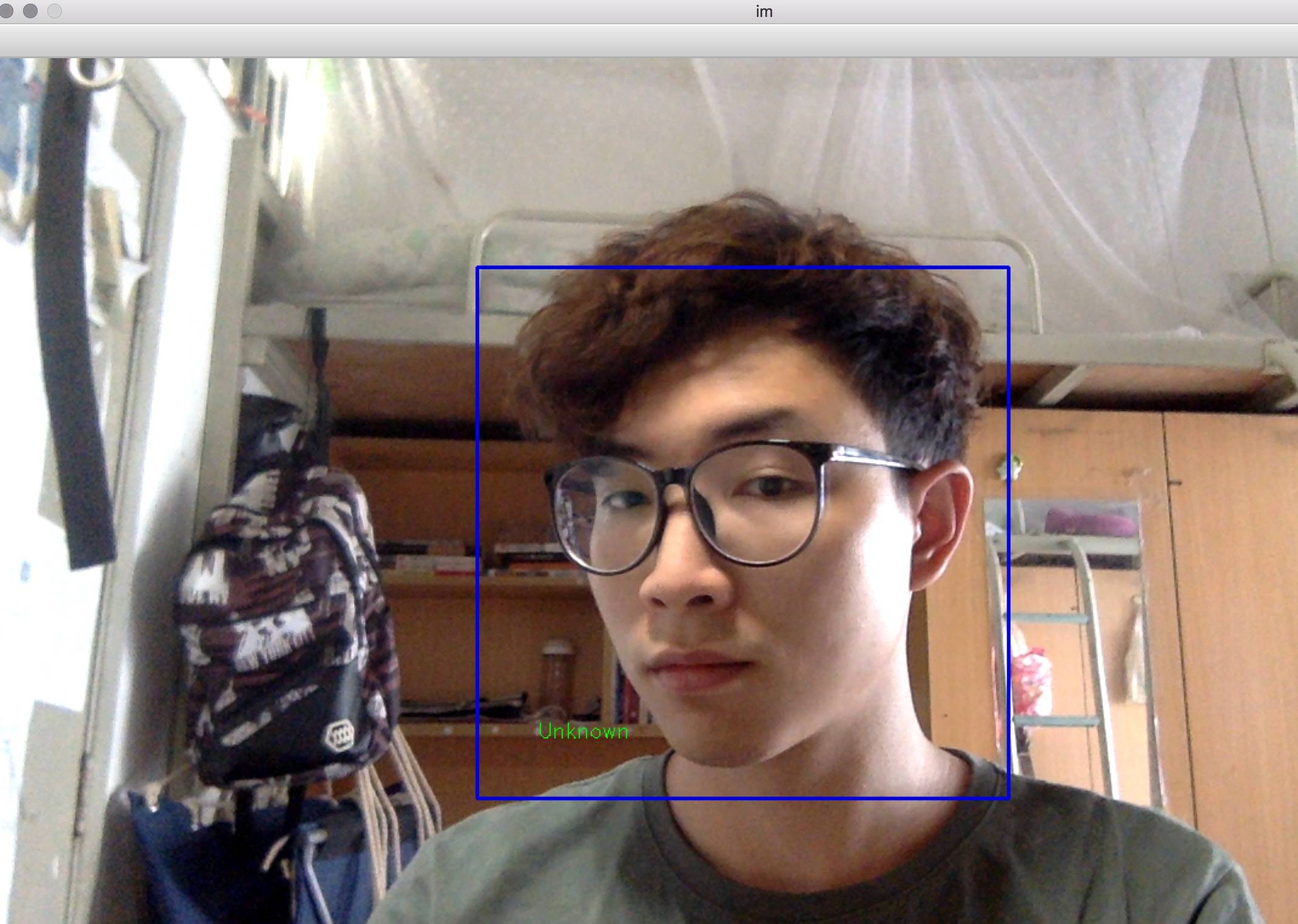
我觉得是素材不够丰富,我回头改改。。。
完整代码
现在的目录:
import cv2
import numpy as np
recognizer = cv2.face.LBPHFaceRecognizer_create()
# recognizer = cv2.createLBPHFaceRecognizer() # in OpenCV 2
recognizer.read('trainner/trainner.yml')
# recognizer.load('trainner/trainner.yml') # in OpenCV 2
cascade_path = "haarcascade_frontalface_default.xml"
face_cascade = cv2.CascadeClassifier(cascade_path)
cam = cv2.VideoCapture(0)
# font = cv2.cv.InitFont(cv2.cv.CV_FONT_HERSHEY_SIMPLEX, 1, 1, 0, 1, 1) # in OpenCV 2
font = cv2.FONT_HERSHEY_SIMPLEX
while True:
ret, im = cam.read()
gray = cv2.cvtColor(im, cv2.COLOR_BGR2GRAY)
faces = face_cascade.detectMultiScale(gray, 1.2, 5)
for (x, y, w, h) in faces:
cv2.rectangle(im, (x - 50, y - 50), (x + w + 50, y + h + 50), (225, 0, 0), 2)
img_id, conf = recognizer.predict(gray[y:y + h, x:x + w])
if conf > 50:
if img_id == 1:
img_id = 'jianyujianyu'
elif img_id == 2:
img_id = 'ghost'
else:
img_id = "Unknown"
# cv2.cv.PutText(cv2.cv.fromarray(im), str(Id), (x, y + h), font, 255)
cv2.putText(im, str(img_id), (x, y + h), font, 0.55, (0, 255, 0), 1)
cv2.imshow('im', im)
if cv2.waitKey(10) & 0xFF == ord('q'):
break
cam.release()
cv2.destroyAllWindows()
先这样吧



17 Comments
110011 · 02/16/2019 at 12:16
这个人脸识别器是否可以识别出多个人脸呢?
煎鱼 · 02/16/2019 at 14:16
可以,在制作数据集的时候就把需要的人脸加入,https://www.mkshell.com/face-recognition-dataset-generator/
110011 · 02/16/2019 at 17:17
哎,这个人工智障也是完美地识别不出我
煎鱼 · 02/16/2019 at 17:28
毕竟这些模型比较简单,想要搞事还是用dl比较好
110011 · 02/16/2019 at 17:27
听说有人用face_recognition模块也做出了人脸识别,有可能准确率会更高哦
striver · 03/17/2019 at 15:54
完美的把所有人都认成我
煎鱼 · 03/17/2019 at 15:58
哈哈,因为这种模型的特征变量太少了,推荐还是使用上更深的神经网络。
striver · 03/17/2019 at 16:03
有推荐学习的资料吗?
煎鱼 · 03/17/2019 at 17:38
DL现在比较流行的框架有Caffe、Tensorflow、Keras等,搜索【人脸识别+框架名】应该会有一堆
fengziChen · 04/18/2019 at 15:39
楼主你好 ,首先很感谢你写的这几篇文档, 在训练之前要先得到训练集,就是得到一堆素材吧算是,然后训练生成yml文件,根据yml文件去识别得出ID,在根据ID判别出是某个人。我觉得训练的那一步 按照你的逻辑 我的理解感觉就相当于是录入,就是把要识别的人脸信息保存为一个yml文件,然后打开摄像头去识别。 我的理解是 这个训练不是应该相当于增强自身属性的一个方式嘛,而不是这种的录入,训练完了录入人脸,然后去识别,训练的越多识别能力越强。不知道我的理解对不对???
煎鱼 · 04/18/2019 at 17:09
yml保存的是参数,我们把人脸看成是输入的自变量(x),id看成是输出的因变量(y),就像是解y=ax方程一样,已知x和y,求参数a。而实际上参数不只有一个a,有很多个,这样看来,录入的过程其实就是有多条方程式,且已知x和y,求出尽可能精确的a参数,然后存放在yml中。
识别的时候,就是从yml中提取a,输入图像自变量x,得到y,y就是id了,就是大概这样的一个过程。
往往你说的录入就是一个拟合的过程,就是参数a不能拿到精确的值,只能尽量精确。那么输入越多的照片来训练(录入),a的值就会越准确。
Epsilon · 12/10/2019 at 19:42
人脸数有没有最大限制?我超过十种就报错了
Nemo · 05/19/2020 at 17:33
大佬厉害了
Frieden · 08/19/2020 at 18:10
大佬我按照你的步骤到最后显示buit-in function id是怎么回事?谢谢
画个饼 · 12/31/2020 at 09:45
你好请问你用过Fisher和Eigen模型训练吗?我用的LBPH模型感觉精度不行,想用其它两种试试,但每次训练都会出错cv2.error: OpenCV(4.4.0) C:\Users\appveyor\AppData\Local\Temp\1\pip-req-build-71670poj\opencv_contrib\modules\face\src\fisher_faces.cpp:81: error: (-210:Unsupported format or combination of formats) In the Fisherfaces method all input samples (training images) must be of equal size! Expected 7921 pixels, but was 7396 pixels. in function ‘cv::face::Fisherfaces::train’。将图片剪裁为一样的大小后还是相同的错误,请问是为什么呢?
煎鱼 · 12/31/2020 at 09:53
是怎么裁剪的,要不统一用“cv2.resize(face, (im_width, im_height))”裁剪下?
画个饼 · 12/31/2020 at 10:05
我是用PIL库的Image里的resize统一剪裁一个文件夹下的所有图像的,但还是不行,回去我试下你的方法,现在在上课,竟然这么快就回复我了真的十分感动,万分感谢!