学架构笔记14:读写分离
“读写分离”属于高性能数据库架构之一。
近十年来,关系数据库由于其ACID特性和功能强大的SQL,依然是业务系统中的关键和核心存储系统,很多场景下的高性能设计的核心部分依然是关系数据库。
关系数据库厂商在单个数据库服务器的性能方面做了很多的技术优化和改进,但是优化和改进的速度总比不上业务的发展速度,必须要考虑以数据库集群的方式来提升总体性能。
读写分离介绍
读写分离基本架构图:
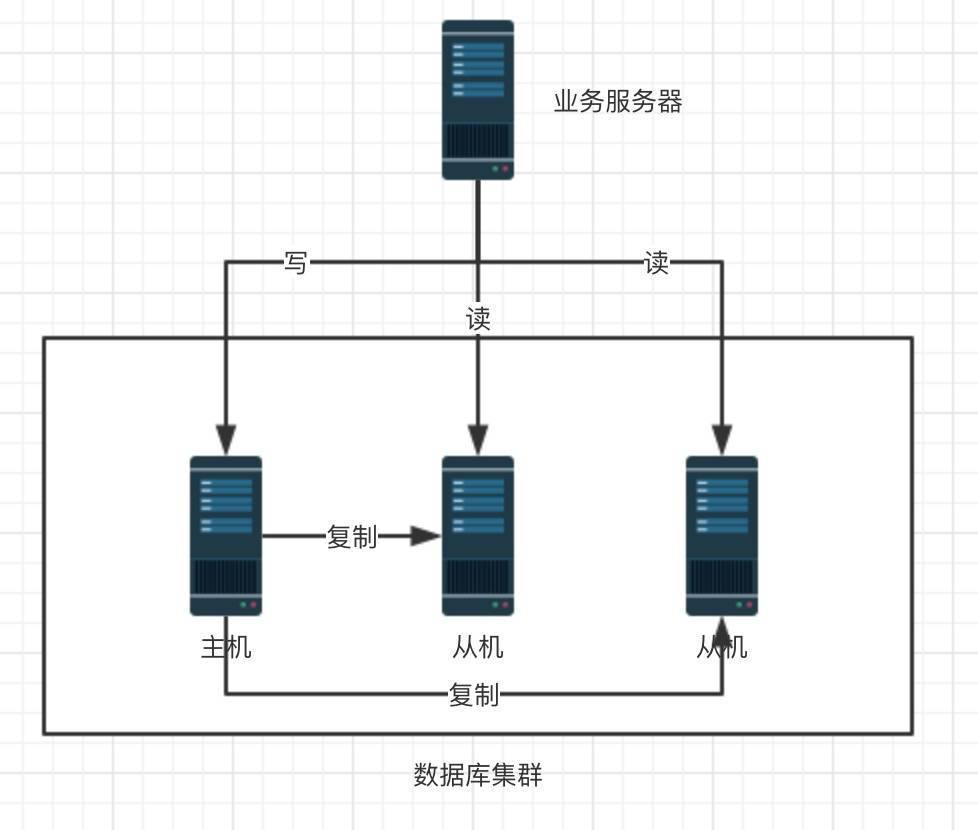
读写分离的规则:
- 数据库分为主(Master)、从(Slave)两类,Master一般只有一个
- 主机负责读写(一般只写),从机只负责读,读写的分发交给业务服务器负责
- 主机将数据复制给从机,完全同步的状态下每个数据库的数据是完全一样的且存储了所有的数据
难点
按照规则来实现读写分离没有什么问题,主要是有两个难点,设计难点会引入设计的复杂度。
复制延迟
由于主从之间的复制也需要时间,因此在某一个时刻,从机的数据可能比主机的数据少了那么几条。而偏偏在这个时候,用户刚写入主机了却在从机读取数据,最终造成“用户操作成功却感觉失败了”的假象。
解决方法是保证写后读一致性(read-after-write consistency):
- 在写入后,读取请求发给主机
- 在从机读取失败则再从主机读取一次
- 关键业务读写走主机,非关键的才读写分离
更详细的情况可以看看Replication中常见的数据一致性的问题。
分配机制
业务服务器将读写分发的逻辑实现有两种方式:程序代码封装、中间件封装。
程序代码封装
指在代码中抽象一个数据访问层,实现读写操作分离和数据库服务器连接管理。
特点:
- 实现简单,可根据业务定制化
- 和编程语言有关,多语言时需要多实现
- 故障情况下(如主从切换),需要改配置且重启
开源实现方案:TDDL(Taobao Distributed Data Layer)
中间件封装
独立出一套系统。
此情况下,业务服务器无需区别读写。在业务服务器看来,该中间件就像是一个数据库。
特点:
- 支持多语言
- 由于中间件需要支持完整SQL语法和协议,实现复杂
- 性能不高
- 业务服务器对主从切换等不感知
开源实现方案:Mysql Proxy、 Mysql Router、 Atlas
总结
读写分离的原理、规则,以及要实现的两个难点。
先这样吧
若有错误之处请指出,更多地关注煎鱼。


